- 阿里云河南授权服务中心--[ 阿里云精英级合作伙伴 ]
- 阿里云河南授权服务中心电话 :0371-56982772
实际上,分区在很多框架中都有这个概念,比如开源框架中的hive等。打个比喻,某城市粮仓里存放麦子,粮仓里按照县城分为很多区域,每个县城都有自己的一块地方,每个县城的麦子放在自己对应的区域上。如果上级领导来检查,想看某县城的麦子情况,那直接可以根据区域来迅速找到该县城的麦子。对应到Maxcompute分区表,粮仓相当于其中一张表,每个区域相当于以这个县城命名的分区。
一,分区表的概念
分区表指的是在创建表时指定分区空间,即指定表内的某几个字段作为分区列。在大多数情况下,用户可以将分区类比为文件系统下的目录。MaxCompute 将分区列的每个值作为一个分区(目录)。用户可以指定多级分区,即将表的多个字段作为表的分区,分区之间正如多级目录的关系。在使用数据时如果指定了需要访问的分区名称,则只会读取相应的分区,避免全表扫描,提高处理效率,降低费用。
使用示例:
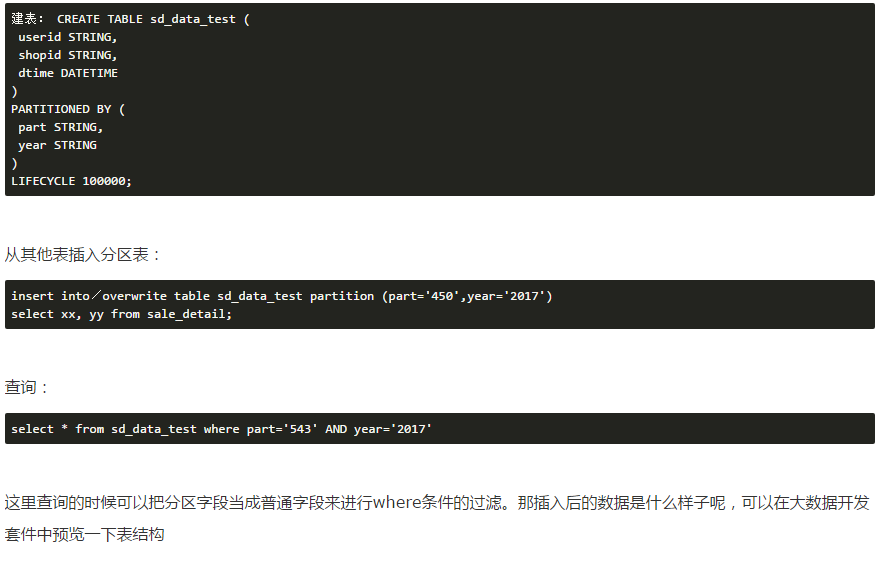
可以看到分区列相当于表中的字段,可以和表中的其他字段一样来使用。一般是放在where条件后抽取数据使用。
在表中实际的结构是什么样呢,其实分区相当于表中的子目录。那么如何查看呢,这里我使用odps的一个
eclipse插件下载表结构。安装eclipse插件可以参考https://help.aliyun.com/document_detail/27981.html?spm=5176.doc27800.6.756.04j9A9
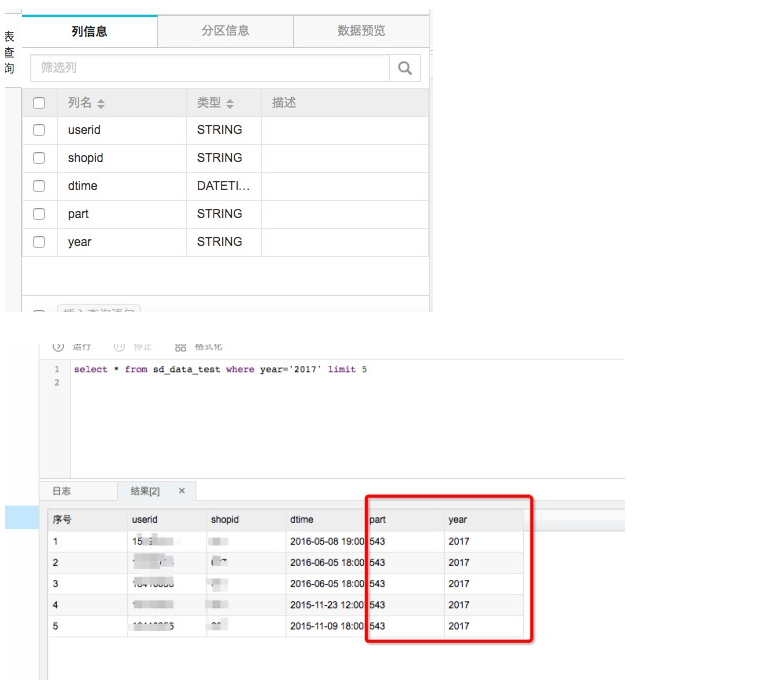
调试代码时会下载表结构和小部分数据。sd_data_test的表结构如图:
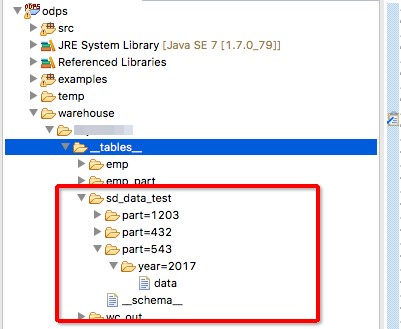
想必看到这个图就很清楚分区列和表字段的关系了。在查询的时候不会扫描全部表,而是去查某个分区目录下的数据,可以有效的提高查询效率。
二,静态分区,动态分区
静态分区和动态分区是对应的。所谓静态分区就是指在插入分区表的时候要指定分区值,比如上面例子

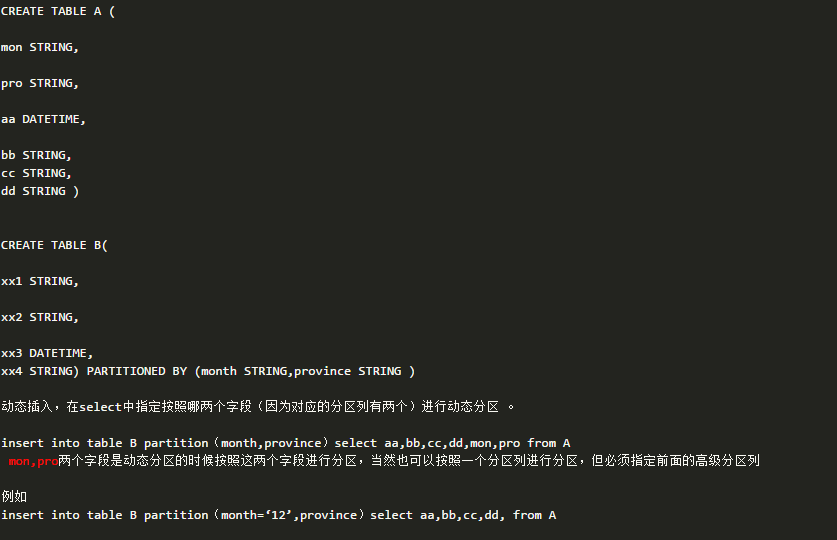
三,odps分区的一些注意事项:
还有一点就是如果动态分区,来源表数据量非常大并且分区字段数据分布不均匀容易产生数据倾斜问题,建议先做好规划,比如先将数据量非常大的那个分区值过滤随后静态分区单独插入。
总结:合理设置分区,可以大幅度提高查询速度降低使用费用,因为Maxcompute收费一部分来源于sql计算,设置分区表在计算时指定计算的分区,参与计算的数据不会扫描全表而是指定的部分分区表数据。
另外从计算性能上来说,如果分区数据过多了也会适得其反影响性能,甚至会超出Maxcompute的限制。所以合理使用分区表会给计算业务带来很好的优化效果。


©2024 aliyunhn.com. All Rights Reserved 中科九洲科技股份有限公司-阿里云河南授权服务中心 豫B2-20080032-14 统计
