支撑双十一的高性能负载均衡是如何炼成的?
发布时间:2018-07-23 16:01
上个月在北京召开的DPDK峰会上,阿里云网络技术专家梁军(刺背)分享了阿里云高性能负载均衡的架构、设计理念,以及在双十一和春晚手淘红包等大流量互联网场景中实践。这篇文章总结了本次大会发言。
负载均衡器是对多台服务器进行流量分发的负载均衡服务。它可以通过流量分发扩展应用系统的服务能力,还可以消除单点故障提升应用系统的可用性。因此负载均衡器得到了广泛的应用,目前已经成为阿里巴巴流量的入口。阿里巴巴新一代的负载均衡器基于DPDK来实现,其提供的高性能与高可用性支撑了阿里巴巴业务的高速发展,尤其是保障了阿里巴巴2017年的双11狂欢节,接受了双11场景下脉冲式海量流量的检验。本PPT将从两个方面来介绍阿里巴巴新一代的负载均衡器:第一,介绍基于DPDK的高性能负载均衡器的实现架构,第二,介绍DPDK负载均衡器的并发会话同步机制,此机制实现了LB在容灾与升级场景下让业务无感知。
基于DPDK开发的阿里负载均衡器
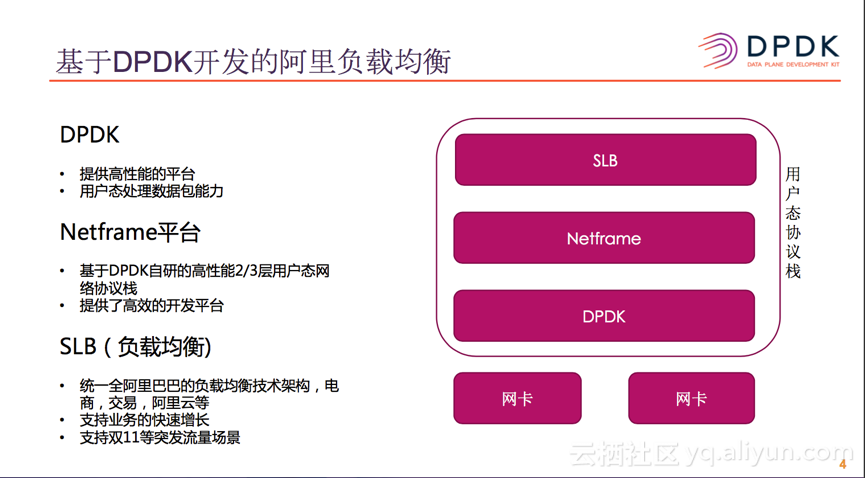
目前整个阿里巴巴使用的负载均匀器,绝大多数都已经替换成基于DPDK自研的负载均衡器。此版本最底层是DPDK,利用DPDK平台提供的便利的高性能技术: 如用户态收发包,hugepage, NUMA等。再一上层是Netframe平台,它是基于DPDK自研的高性能2/3层用户态网络协议栈,实现了2层的MAC地址转发,3层的路由查找转发以及动态路由协议等,而且还提供了各类丰富的库,最终于类似Netfilter钩子的形式提供给上层的应用程序使用。阿里巴巴当前主力的SLB就是基于Netframe平台研发的,基于此平台SLB直接通过钩子的方式接收与发送数据包,只需要关心业务自身的数据流,因此可以快速,高效的开发网络应用程序。目前此版本的SLB已经广泛使用在了阿里的电商交易,交易支付等业务上,而且阿里云公有云服务器上对外提供的SLB产品也是基于此版本。
在双11大促活动中,公网入口的流量主要分为两大类:一类是用户访问阿里的流量,首先经过CDN网络,再由CDN网络回源到提供服务的应用,在回源时会经过SLB,由SLB提供负载均衡服务,通常这种流量模式占绝大多数。另一类访问流量是直接由SLB提供服务,用户的流量直接经过SLB就到达后端的应用,这种流量模式只占一小部分。两个流量模型,SLB都在流量入口的位置,占据着非常重要的位置,因此对SLB的稳定性都提出了很高的要求。
基于DPDK 的负载均衡支撑双11活动
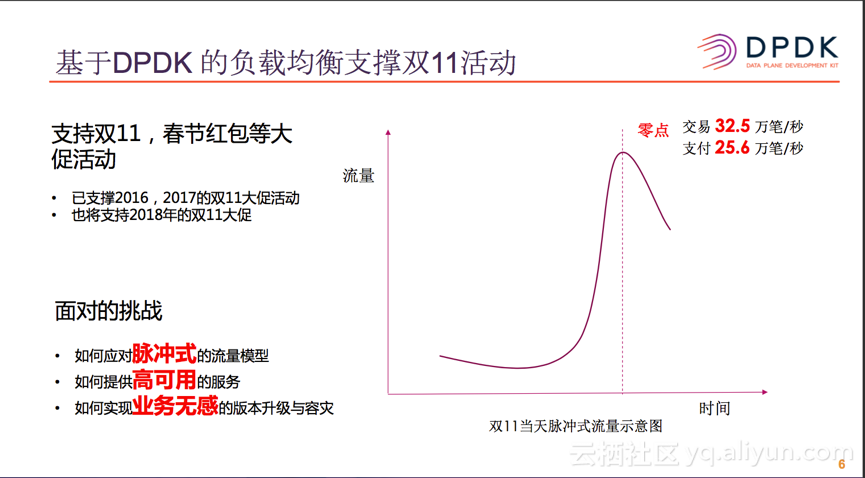
基于DPDK版本的负载均衡器,已经平衡了支持了近两个的双11和春节红包活动,上图中是2017年双11流量的示意图, 从图中我们可以看出,双11当晚的流量是一个脉冲式的图形,这是由于双11当天,有很商品需要在0点之后才能抢购,而通常这部分商品的数量是很有限的。我们可以看到2017年双11当天的交易峰值为32.5万笔/秒,支持峰值是25.6万笔/秒,这种脉冲式的流量模型对SLB带来了很大的挑战。
1. 如何应用脉冲式的流量模型,提供稳定的服务?
2. 如果提供一个高可用的服务,来应对随时都可以发生的设备与网络的异常?
3. 如何实例业务无感的版本升级与容灾?
高性能的负载均衡服务
高性能的负载均衡器基于DPDK平台,利用了DPDK平台的优化,打造了极轻量的高效数据转发面。在转发面中,无中断,无抢占,无系统调用,无锁,通过将核心数据结构cache line 对齐,减少CPU cache miss, 通过使用hugepage 减少TLB的miss,通过将关键数据结构NUMA话,减少CPU跨NUMA访问的延时。在应用程序的处理逻辑上,也秉承着控制面与转发面分离的设计原则,保持高效轻量的转发面,让转发面尽量少的处理非数据包转发相关的事情,复杂的管理操作,调度,统计等都放到控制面来处理。
高性能的负载均衡器除了利用DPDK平台的先天优势以及控制面与转发面相分离的平台设计,SLB自身还实现了软硬件结合的转发架构。从client到达SLB的数据包,经过网卡的RSS(Receive Side Scaling),将流量均匀的打散到不同的CPU上,由于阿里的SLB使用的FNAT的转发模式,每个CPU都有自己独立的local address,因此从SLB发往后端RS的数据包,都被替换成了每个CPU自己的local address。这样保证了从RS回来了数据包经过网卡的FDIR(Flow Director)逻辑之后可以到达从client方向过来的流同一个CPU,从而从机制与转发架构上实现了“进出同CPU”的架构,在此架构之后业务上实例了多CPU并发处理的逻辑,让数据结构Per-CPU化,CPU可以完全并行化的处理数据包,使性能大幅的提升,同时,此并发处理的架构,可以充分利用当前多CPU服务器架构,为后续CPU的持续增加,提升了性能不断提升的可能。
SLB利用DPDK平台的先天优势,使用控制面与转发面相分离的平台设计原则, 采用CPU并行化处理的转发构架,其性能得到了很大的提高。在64字节小包的场景下,转发PPS由内核版本的10Mpps提升到了39Mpps, 连接新建的性能也由内核版本的2.7Mcps提升到了6.9Mcps。正是由于DPDK版本SLB性能的大幅提升,才保障了近两年双11脉冲式的增长的突发流量场景。
无感容灾与升级
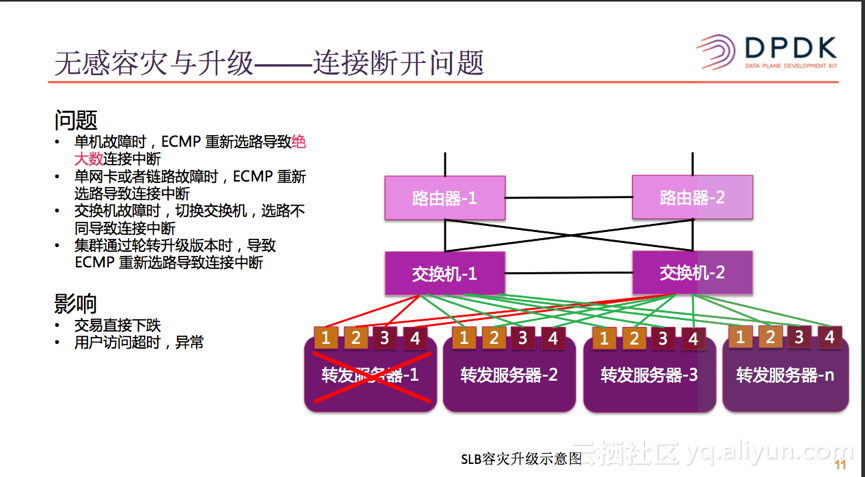
上图是SLB的容灾升级示意图,SLB的部署是可水平扩展的集群化部署模式,多台服务器之间发布相同的VIP路由,在交换机侧形成ECMP的路由,提供了多个维度的容灾能力。但是在没有连接同步之前,由于CPU,内存,硬盘等故障会导致整个转发服务器不可用,在网络收敛之后,ECMP会重新选路,导致绝大多数连接在重新选路之后,不同到达之前的转发服务器上,从而导致已有的连接中断。单网卡或者网卡与交换机之间的故障,交换机自身故障,或者SLB通过轮转升级等多重情况下,都会导致ECMP重新选路,导致已有的连接中断。已有连接中断,特别是长连接中断,导致直接交易额直接下跌,对于用户侧会感觉到访问超时,或者报错,对于用户的体感也非常不好。
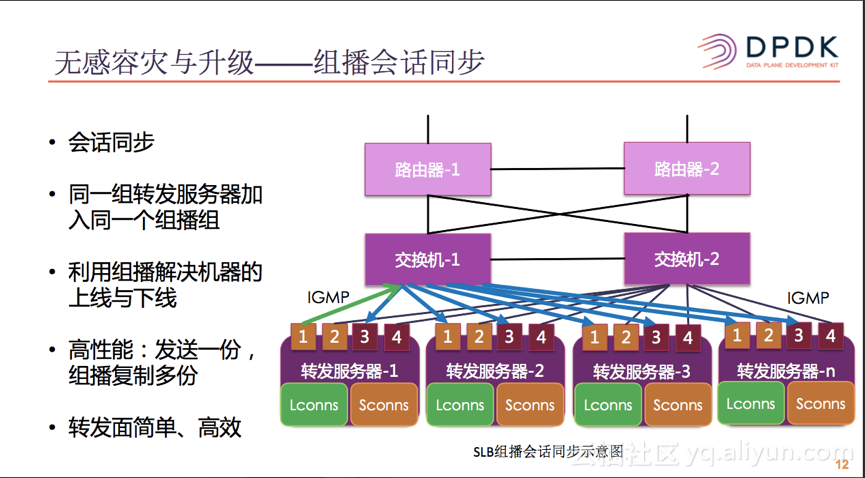
SLB使用了会话同步的机制来解决了升级与容灾场景下长连接中断的问题。同一个组的服务器(如图中的4台转发服务器)会加入到同一个组播组中,当SLB应用程序启动之后,它会自己加入到对应的组播组中,服务器下线或者重启,超时后自动从组播组中删除。使用组播技术之后,可以简化会话同步机制中,机器上线与下线的问题。使用组播技术之后,将原本需要复制多份,分别发送给其它服务器的组播包,现在只需要发送一份,数据包的复制offload给交换机,由交换机的硬件完成,让SLB的转发面简单,高效,高性能。
有了会话同步之后,会话分为两类:一类是本地会话Lconns,另一类是同步的会话Sconns。会话同步时,只会将本地的会话同步给他们设备,接收同步请求的服务器会更新Sconns的超时时间以及其它信息。在发生容灾切换时,转发服务器的Sconns如果进行了数据包的转发,就会自动切换成Lconns。