阿里集团自2012年培养了第一位“东八区” HBase Committer,到今天,阿里巴巴已经拥有3个PMC,6个Committer,阿里巴巴是中国拥有最多HBase Committer的公司之一。他们贡献了许多bug fix以及性能改进feature等,很可能你在用的某个特性,正是出自他们之手。他们为HBase社区,也为HBase的成长贡献了一份宝贵的力量。当然,也孕育了一个更具有企业针对性的云上HBase企业版存储系统——ApsaraDB for HBase。
ApsaraDB for HBase2.0是基于开源HBase2.0基础之上,融入阿里HBase多年大规模实战检验和技术积累的新一代KV数据库产品,结合了广大企业云上生产环境的需求,提供许多商业化功能,比如 HBase on OSS、HBase云环境公网访问、HBase on 本地盘、HBase on 共享存储、冷热分离、备份恢复、HBase安全机制等等,是适合企业生产环境的企业级大规模云KV数据库。
ApsaraDB for HBase2.0,源于HBase,不仅仅是HBase!
二、深入解读云HBase架构
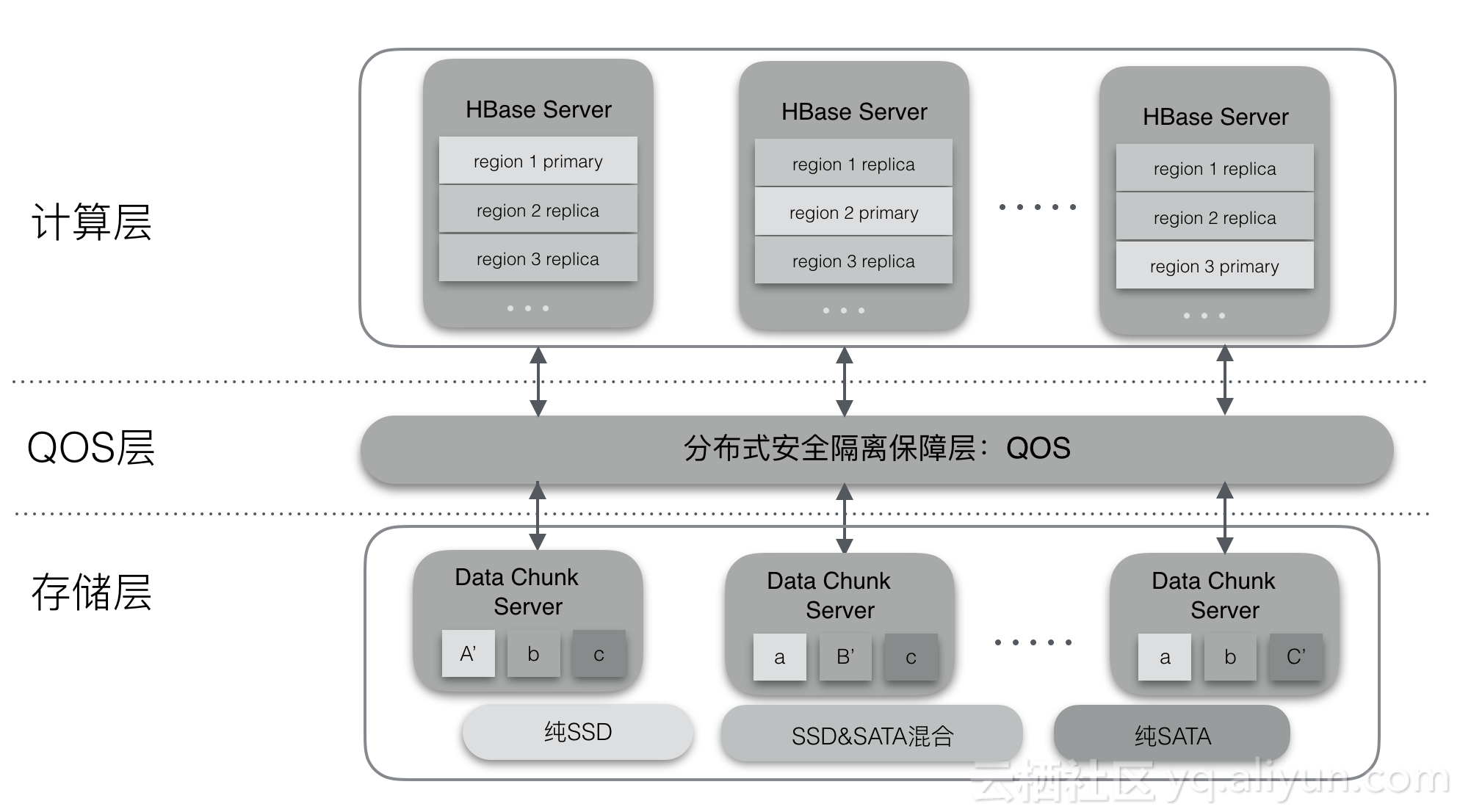
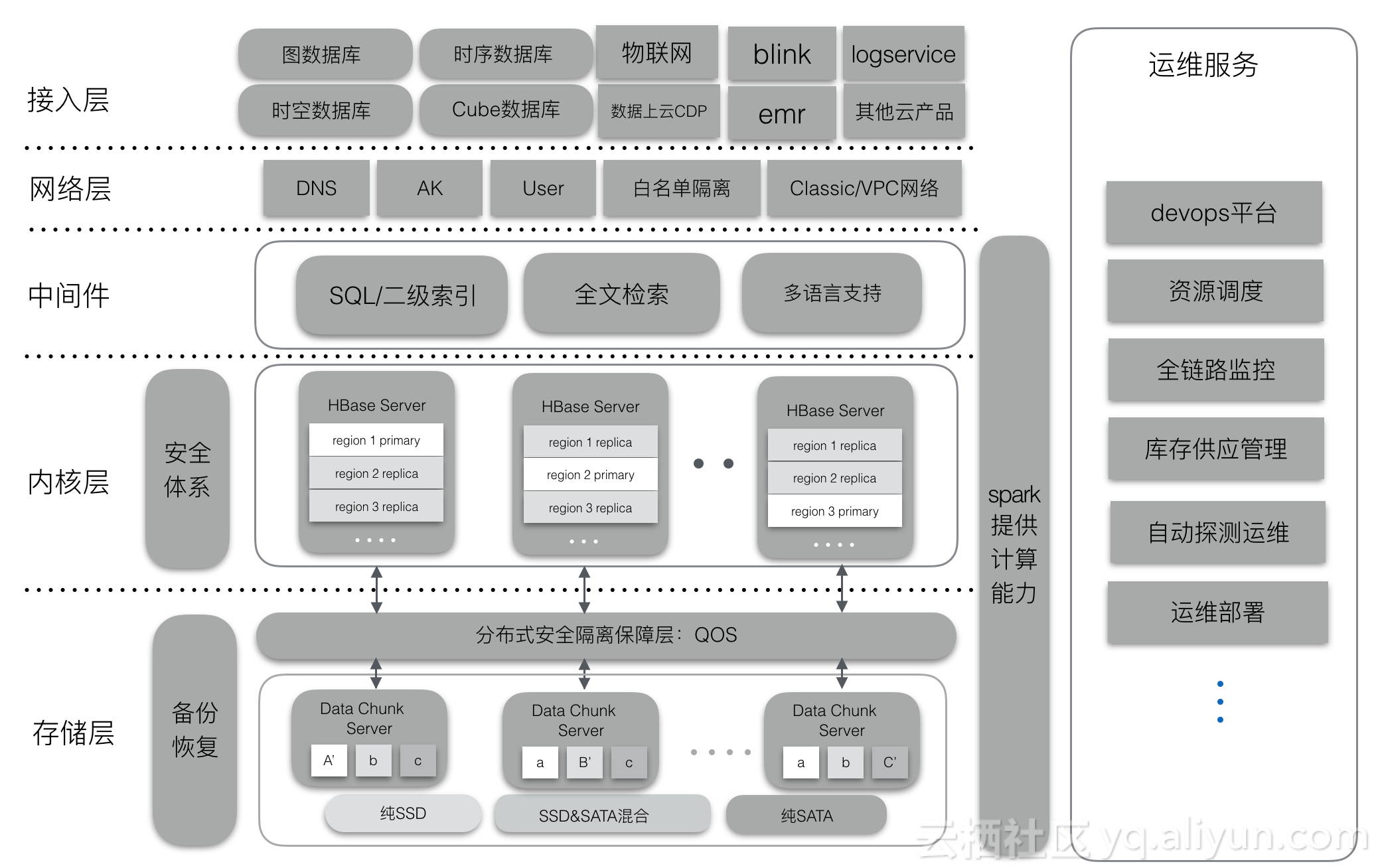
ApsaraDB for HBase2.0是建立在庞大的阿里云生态基础之上,重新定义了HBase云上的基础架构,对企业云上生产需求更有针对性,满足了许多重要的云上应用场景。其中最常见的有:存储计算分离、一写多读、冷热分离、SQL/二级索引、安全等。下面针对这些场景简单介绍一下ApsaraDB for HBase2.0的基础架构。
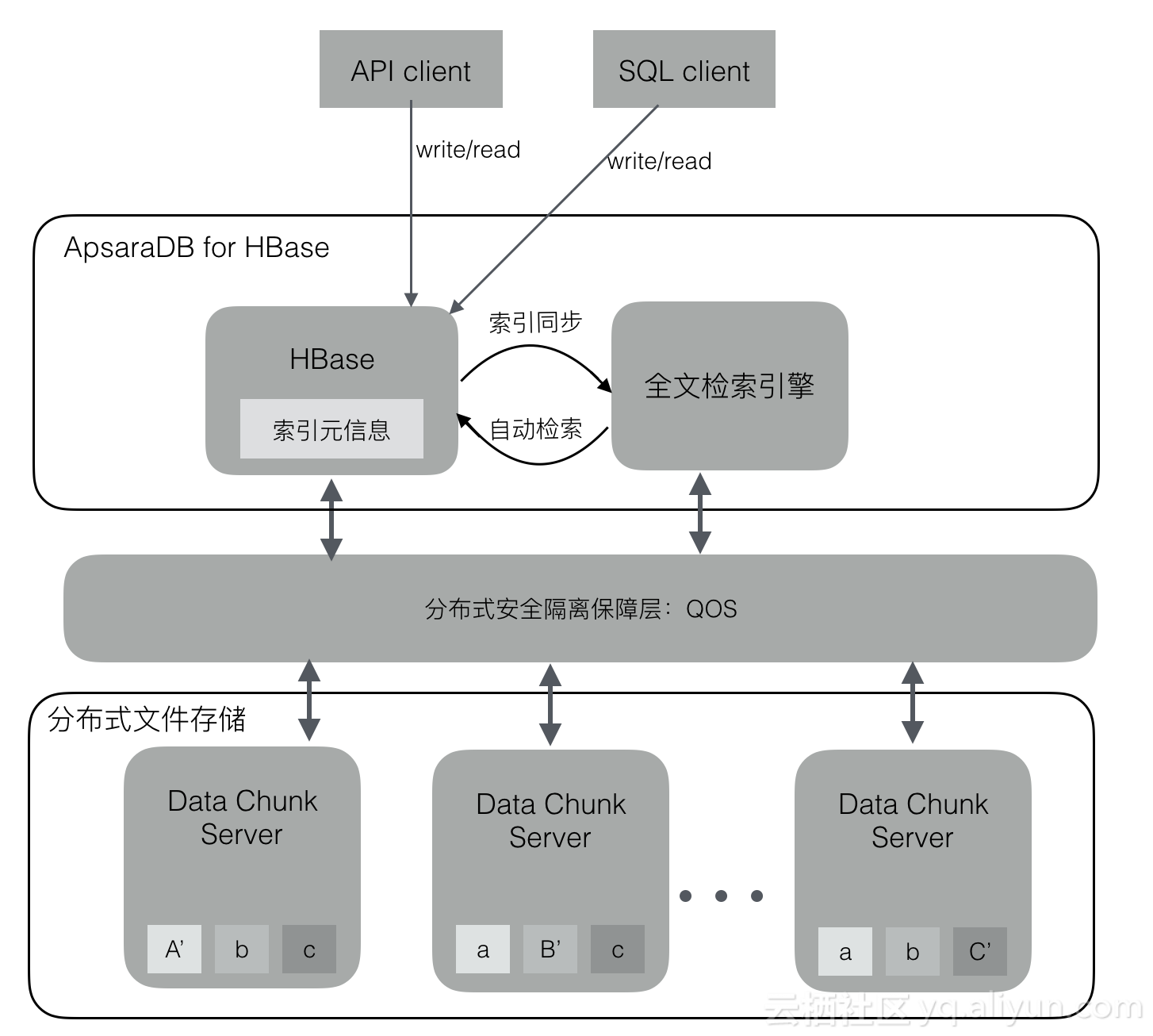
ApsaraDB for HBase2.0支持更完善的SQL接口、二级索引以及全文索引,用户可以使用熟悉的SQL语句操作HBase系统;并且支持二级索引的创建、全量重建索引,以及增量数据自动同步索引的功能;2.0版本还将支持全文索引检索功能,弥补了HBase不能模糊检索的缺陷,把全文检索的功能引入HBase系统当中。
如上图,ApsaraDB for HBase2.0体系内置solr/phoenix内核引擎,进行了深度改造与优化,支持SQL/API方式操作数据库,二级索引支持:全局索引、本地索引、全文索引等。索引支持全量重建、增量数据自动同步更新。在检索查询的时候,索引对用户透明,HBase内部根据索引元信息自动探测用户查询是否需要利用索引功能,增强了HBase系统检索能力,有利于企业在云HBase业务上构建更复杂的检索场景。
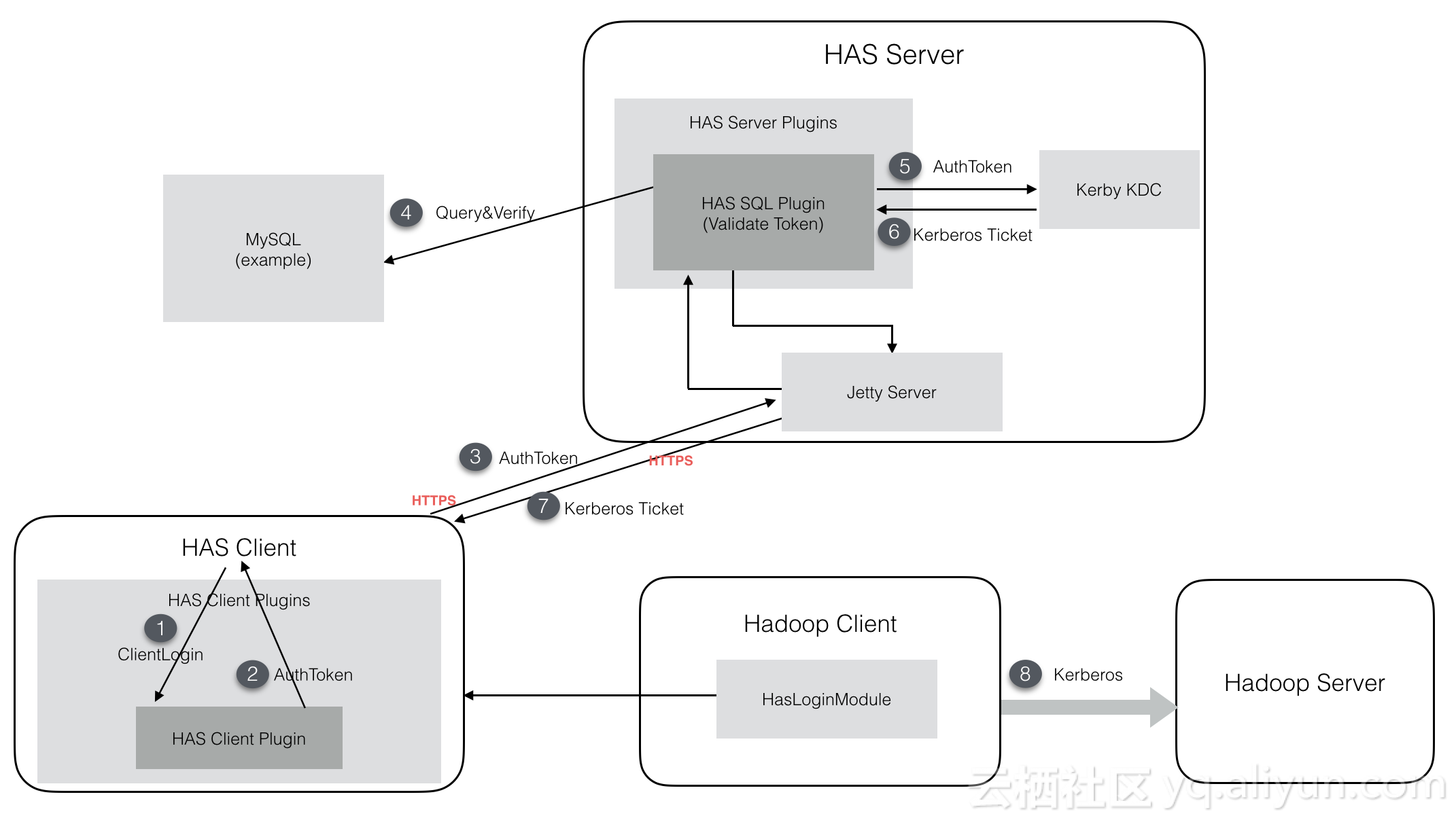
ApsaraDB for HBase2.0基于Alibaba&Intel 合作项目Hadoop Authentication Service (HAS) 开发了一套属于云HBase的认证授权体系,兼容了Hadoop/HBase生态的Kerberos协议支持,并使用人们熟悉的账户密码管理方式,允许对用户访问HBase的权限进行管理,兼容默认ACL机制。
如上图,ApsaraDB for HBase2.0安全体系基于HAS开发,使用Kerby替代MIT Kerberos服务,利用HAS插件式验证方式建立一套人们习惯的账户密码体系,用户体验更友好。
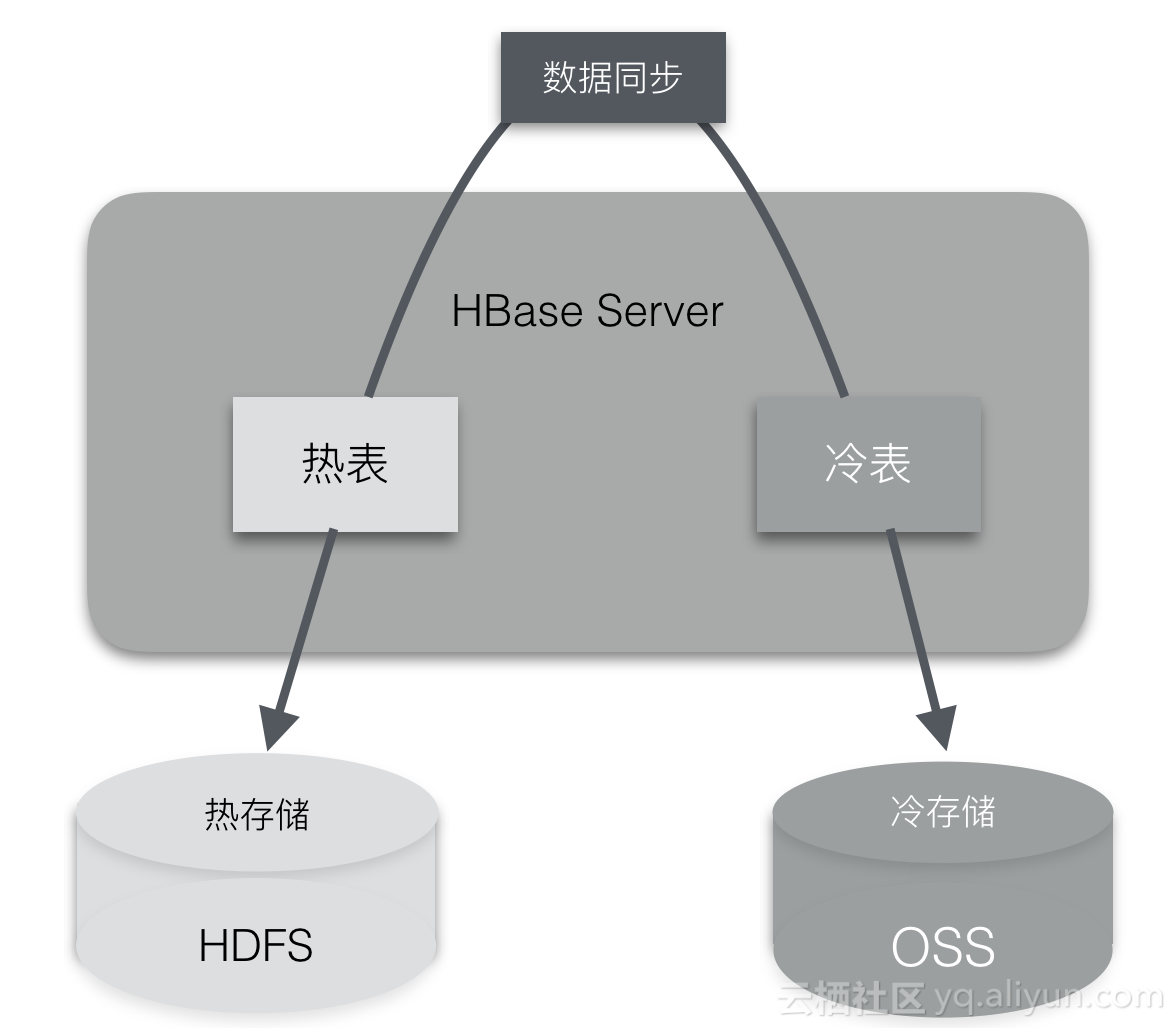
2.6 备份恢复
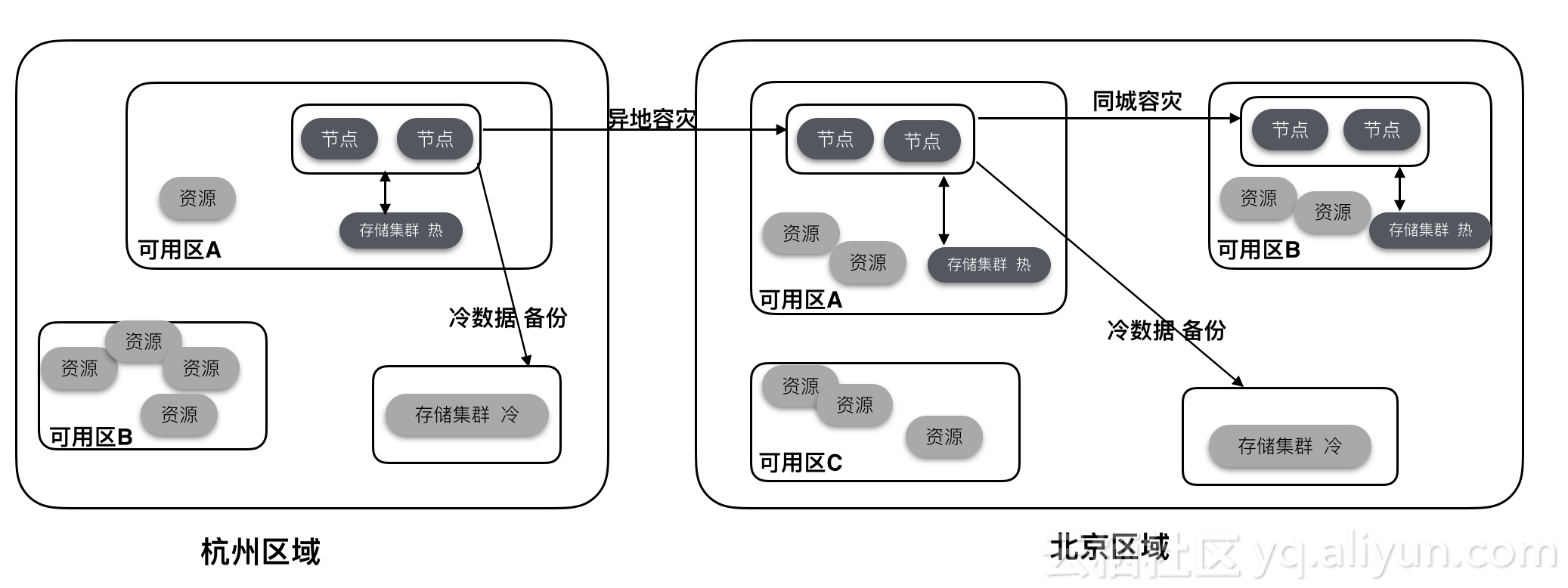
大数据时代,重要的信息系统中数据就是财富,数据的丢失可能会造成不可估量的损失。对于这种数据重要级别较高的场景,应该要构建一套灾难备份和恢复系统架构,防止人为操作失误、自然灾害等不可避免的偶然因素造成的损失。ApsaraDB for HBase2.0构建在云体系下,支持全量、增量备份,同城/异地灾备功能。
开源HBase在2010年正式成为Apache顶级项目独立发展,而阿里巴巴同步早在2010年初已经开始步入HBase的发展、建设之路,是国内最早应用、研究、发展、回馈的团队,也诞生了HBase社区在国内的第一位Committer,成为HBase在中国发展的积极布道者。过去的8年时间,阿里累积向社区回馈了上百个patch, 结合内部的阿里巴巴集团“双十一”业务等的强大考验,在诸多核心模块的功能、稳定性、性能作出积极重大的改进和突破,孕育了一个云上HBase企业版KV数据库ApsaraDB for HBase。
ApsaraDB for HBase发展至今,已经开始进入了2.0 时代。ApsaraDB for HBase是基于开源HBase2.0版本,结合阿里HBase技术和经验的演进过来,其完全兼容HBase2.0,拥有HBase2.0的所有新特性的同时,更享受阿里专家&HBase Committer们在源码级别上的保驾护航。2.0相比1.x之前版本在内核上有了许多改进,内核功能更稳定、高效、延时更低,功能更丰富。下面我们来介绍一下这些重要的功能特性。
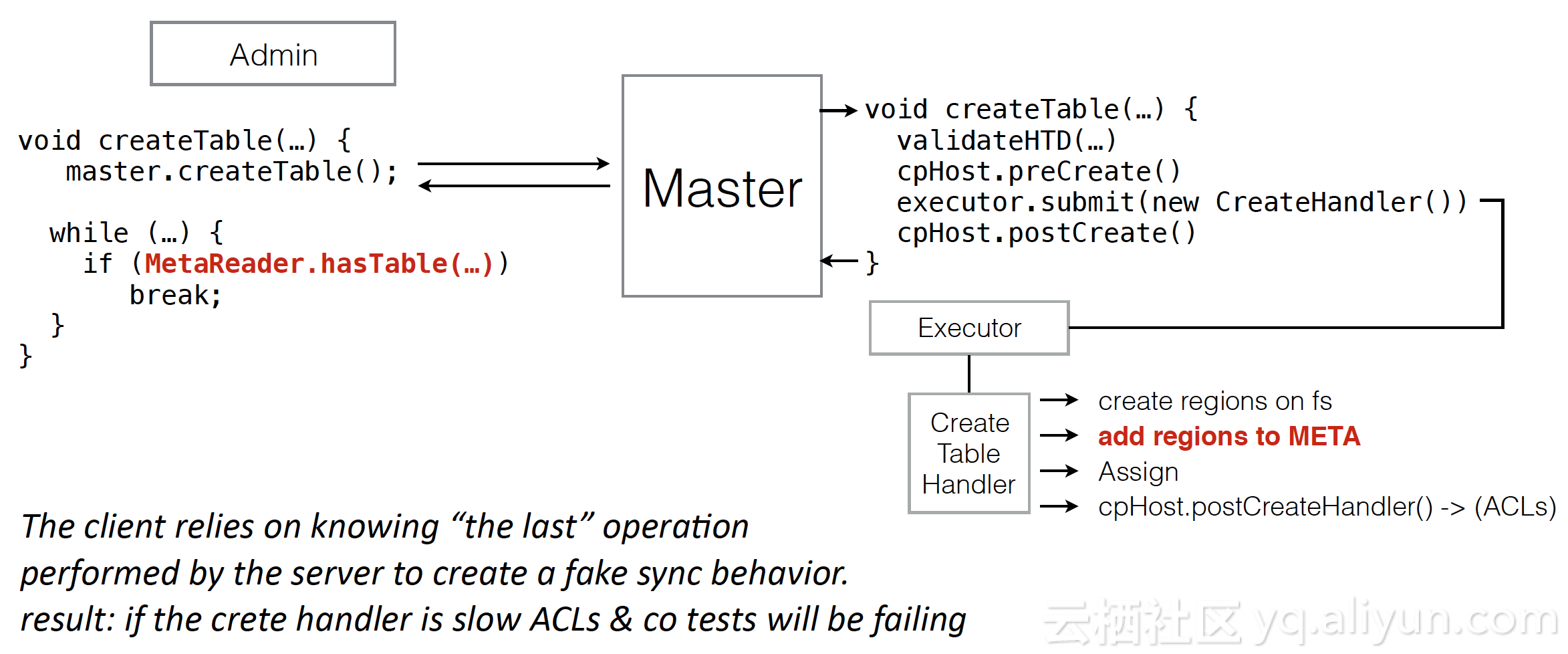
针对这类问题,ApsaraDB for HBase2.0内核做了两个核心的改动,一个是引入ProcedureV2,解决诸如上述分布式多步骤流程处理的状态最终一致性问题;二个是基于ProcedureV2基础上,改造了AssignmentManager,使其在region上线过程被异常或灾难中断后,进程恢复时可以自动回滚中间残留状态信息,重试中断步骤并继续执行。最终避免了类似RIT的问题,实现“NO more HBCK, NO more RIT”,提供稳定性,降低运维成本。
如上图,最常见的就是状态机Procedure,定制每次状态在继续向下执行的时候,应该做哪些操作,以及在中断恢复后,应该处理的rollback工作。回想上面创建表的例子,如果我们同样在"add regions to META"的时候失败了,那么我们在恢复之后,就可以根据这个状态信息,继续执行剩下的步骤,只有当这个procedure 完成的时候,这个create table的procedure 才算完成。当然,client判断是否创建表成功也不再是使用 “MetaReader.hasTable”来利用中间状态得到结果,而是直接根据createTable的procedure Id来查询是否任务完整执行结束。可以看出,在使用ProcedureV2和之前的线程处理有了很大的改进,更灵活的处理业务进程被中断时的各种异常情况。
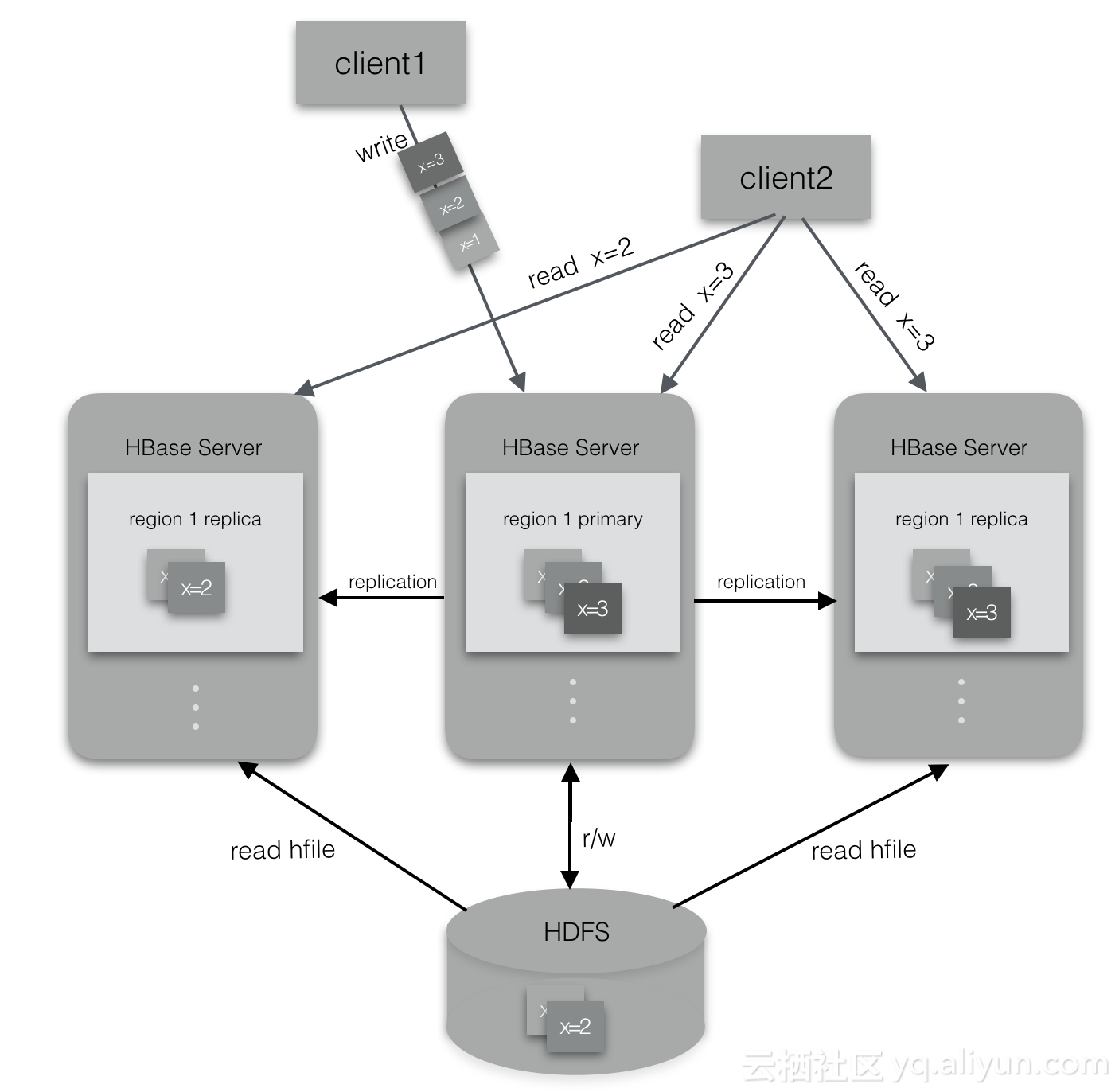
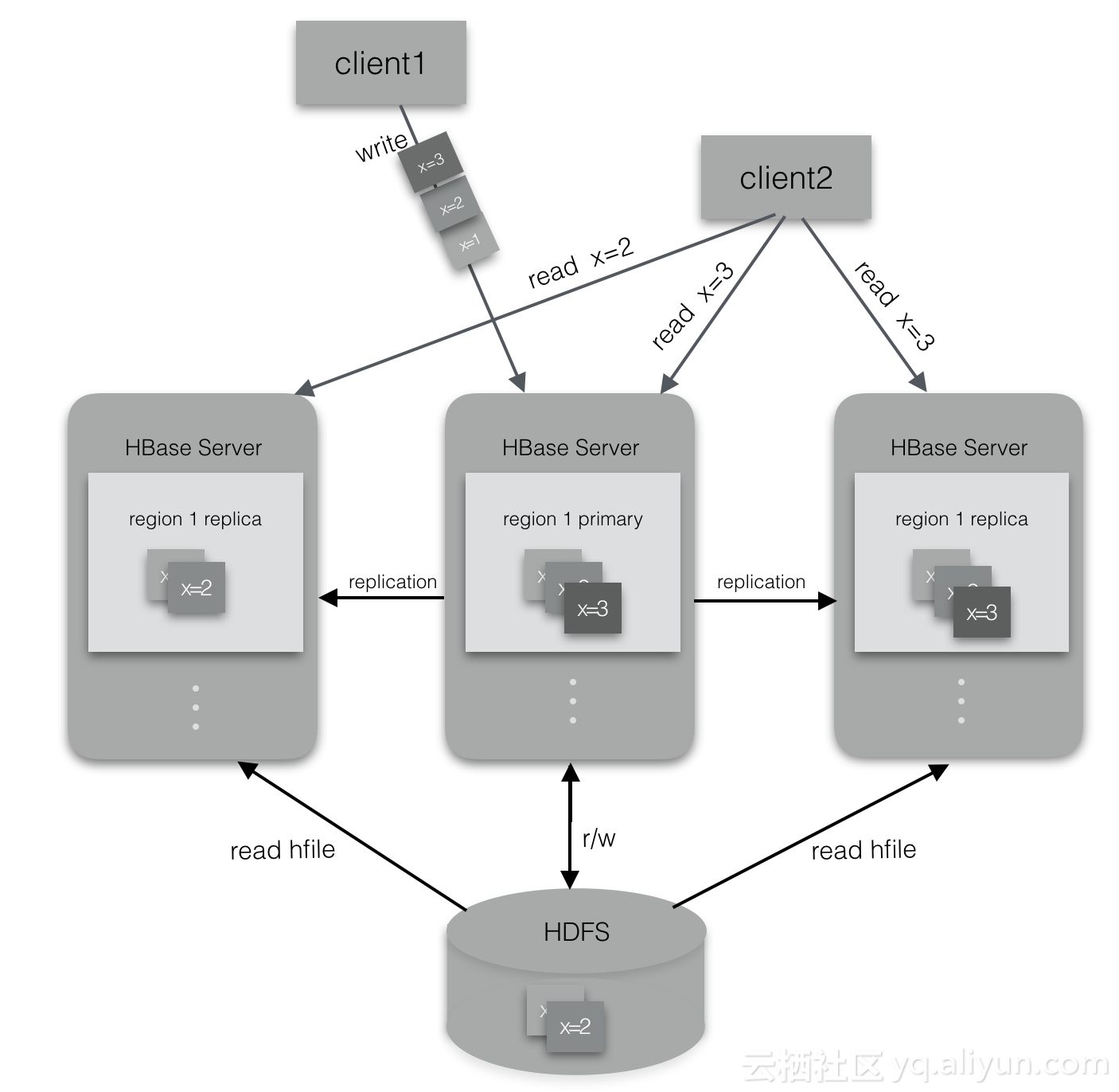
ApsaraDB for HBase2.0引入region多副本机制,当用户对某个表开启此功能时,表的每个region会被分配到多个RegionServer上,其中replicaId=0的为主region,其他的为从region,只有主region可以写入,从region只能读取数据。主region负责 flush memstore成为hfile;从region一方面根据hfile列表类读到数据,另一方面对于刚写入主region但还没有flush到hdfs上的数据,通过replication同步到从region的memstore。