MongoDB 4.0 RC 版本强势登陆
发布时间:2018-05-31 11:44
MongoDB 因其灵活的文档模型、可扩展分布式设计广受开发者喜爱,在此基础上,MongoDB 4.0 推出了更强大的功能支持,目前4.0第一个RC版本已经发布,本文将介绍 MongoDB 4.0 核心的一些新特性。
多文档事务(Multi-Document ACID Transaction)
结合 MongoDB 文档模型内嵌数组、文档的支持,目前的单文档事务能满足绝大部分开发者的需求。为了让 MongoDB 能适应更多的应用场景,让开发变得更简单,MongoDB 4.0 将支持复制集内部跨一或多个集合的多文档事务,保证针对多个文档的更新的原子性。而在未来的 MongoDB 4.2 版本,还会支持分片集群的分布式事务。
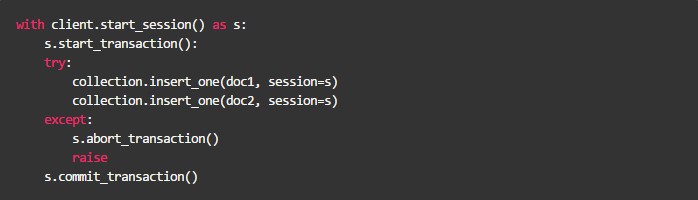
MongoDB 的事务接口非常简单,开发者只需要将「需要保证原子性的更新序列」放到一个 session 的
开始事务 与
提交事务 之间即可。
如下是 Python API 使用事务的例子
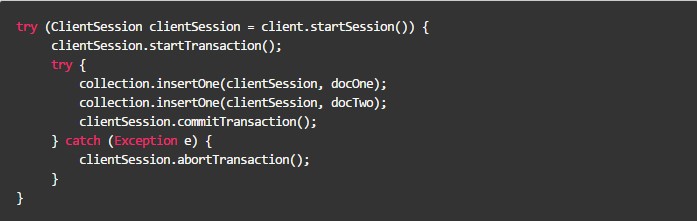
如下是 Java API 使用事务的例子
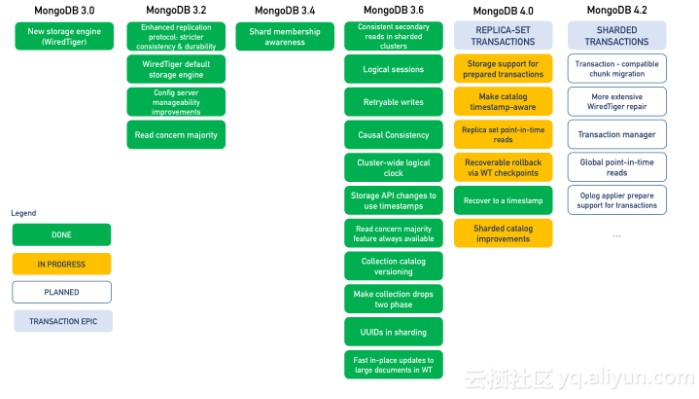
事务是 MongoDB 开发团队经过3年多努力的结果,从3.0版本引入 WiredTiger 、到3.2版本支持 ReadConcern、3.6 支持 Causal Consistency 等很多工作都是在为事务功能做准备,最终在4.0版本将整个事务的API提供给用户,帮助用户更好的构建应用。
聚合类型转换( Aggregation Pipeline Type Conversions)
灵活的文档模型是 MongoDB 相比传统关系型数据库的一大优势,应用开发者无需为存储的数据预先定义结构(或者模式),这使得开发者能快速的应对开发需求的迭代;在灵活的同时,MongoDB 还提供了 schema validation 功能,使得开发者可以根据需要定义文档数据的模型。
MongoDB 的文档允许用户灵活的写入各种类型的数据字段,这给消费数据带了一定的复杂性,比如一些数据分析的场景,应用通常希望某个字段的数据拥有统一的类型,以方便数据处理。
MongoDB 4.0 引入了新的聚合操作符 $convert, 允许用户在 aggregation pipeline 里将文档的字段转换成统一的类型输出,使得数据消费端,比如 MongoDB BI 工具、Spark Connectors 以及其他 ETL 工具能更简单的处理 MongoDB 数据。
非阻塞的备节点读(Non-Blocking Secondary Reads)
为了确保备节点上的读与主节点保持相同的因果一致性语义,MongoDB 备节点在批量应用 oplog 的时候会阻塞读请求,这使得在高写入负载下,备节点上读的平均延时通常比主节点更高。
借助事务功能中 storage engine timestamps and snapshots 的实现,引擎层可以很容易的实现「指定时间戳快照读取的功能」,使得备节点上的读请求无需阻塞等待就能读到一致时间点的数据。这个特性将极大的提升 MongoDB 读扩展的能力。
迁移速度提升40%(40% Faster Data Migrations)
应用在不断演进过程中,其负载特性也在不断发生变化,这就要求数据库具备扩展的能力,及时适应应用的负载变化。MongoDB 分片集群支持实时的添加、移除shard 节点,并能在各个 shard 之间自动迁移数据来均衡负载。
MongoDB 4.0 支持在迁移数据的过程中,并发的读取(源端)和写入(目标端),使得迁移的性能提升了约 40%, 使得新添加的节点能更快的承载业务压力,让分片集群发挥最佳效果。
扩展修改订阅(Extensions to Change Streams)
MongoDB 3.6 推出了修改订阅( Change Streams)的功能,使得用户能实时的获取数据的修改,同时通过 Change Streams 还能很方便的实现多数据中心跨复制集的数据同步。MongoDB 4.0 进一步扩展 Change Streams 功能,可以实现分片集群维度的修改订阅。