在阿里云上轻松部署Kubernetes GPU集群,遇见TensorFlow
发布时间:2017-09-25 14:34
摘要: Kubernetes在版本1.6后正式加入了Nvidia GPU的调度功能,支持在Kubernetes上运行运行和管理基于GPU的应用。而在2017年9月12日,阿里云发布了新的异构计算类型GN5,基于P100 nvidia GPU, 提供灵活强悍的异构计算模型,从基础设施到部署环境全面升级,可有效提升矩阵运算、视频识别、机器学习、搜索排序等处理计算效率。
Kubernetes在版本1.6后正式加入了Nvidia GPU的调度功能,支持在Kubernetes上运行运行和管理基于GPU的应用。而在2017年9月12日,阿里云发布了新的异构计算类型GN5,基于P100 nvidia GPU, 提供灵活强悍的异构计算模型,从基础设施到部署环境全面升级,可有效提升矩阵运算、视频识别、机器学习、搜索排序等处理计算效率。当Kubernetes和GPU在阿里云上相遇,会有什么样美好的事情发生呢?
在阿里云的GN5上部署一套支持GPU的Kubernetes集群是非常简单的,利用ROS模板一键部署,将阿里云强大的计算能力便捷的输送到您的手中。不出10分钟,您就可以开始在阿里云的Kubernetes集群上开始您的Kubernetes+GPU+TensorFlow的深度学习之旅了。
前提准备
-
您需要开通容器服务、资源编排(ROS)服务和访问控制(RAM)服务。登录 容器服务管理控制台、ROS 管理控制台 和 RAM 管理控制台 开通相应的服务。
-
所创建的资源均为按量付费,根据阿里云的计费要求,请确保您的现金账户余额不少于 100 元。
-
目前,按量付费的异构计算gn5需要申请工单开通。 请登录阿里云账号后 ,按照如下内容提交 ECS 工单
我需要申请按量付费的GPU计算型gn5,请帮忙开通,谢谢。
当审批通过后,您就可以在 ECS控制台 的 按量付费 的计费方式下查看GPU节点是否可用。
使用限制
目前仅支持华北2(北京),华东2(上海)和华南1(深圳)创建Kubernetes的GPU集群。
集群部署
在本文中, 我们提供了部署单Master节点,并可以配置worker的节点数,同时可以按需扩容和缩容,创建和销毁集群也是非常简单的。
-
选择ROS创建入口
-
单击此处创建一个位于华北2的GPU Kubernetes集群
-
单击此处创建一个位于华东2的GPU Kubernetes集群
-
单击此处创建一个位于华南1的GPU Kubernetes集群
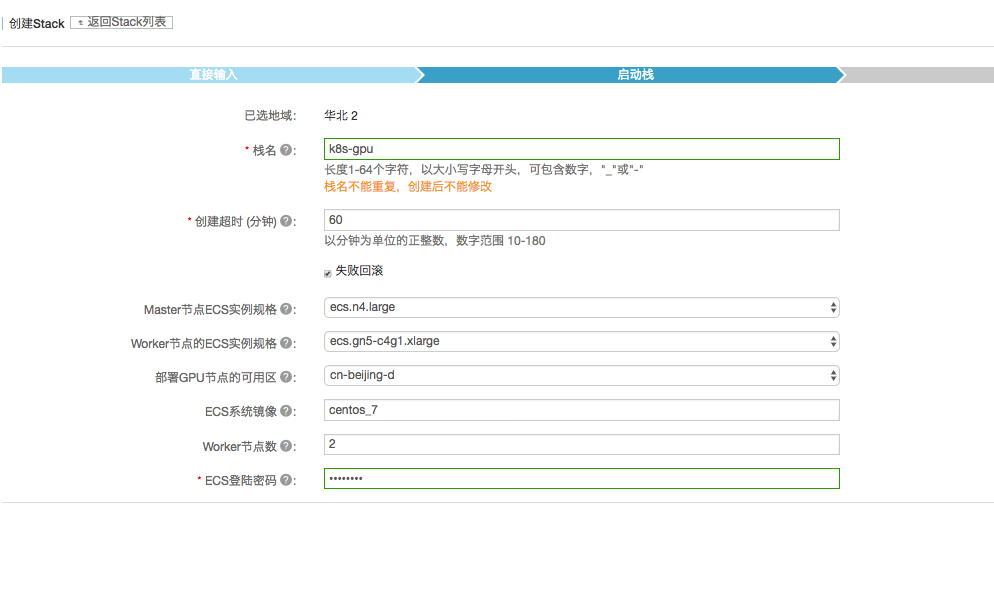
2. 填写参数并单击 创建
-
栈名:所部署的 Kubernetes 集群属于一个 ROS 的栈,栈名称在同一个地域内不能重复。
-
创建超时:整个部署过程的超时时间,默认为 60 分钟,无需修改。
-
失败回滚:选择 失败回滚 时,如果部署过程中发生不可自动修复性错误,将删除所有已创建资源;反之,已创建资源将被保留,以便进行问题排查。
-
Master节点ECS实例规格:指定 Master 节点所运行的 ECS 实例的规格,默认为 ecs.n4.large。
-
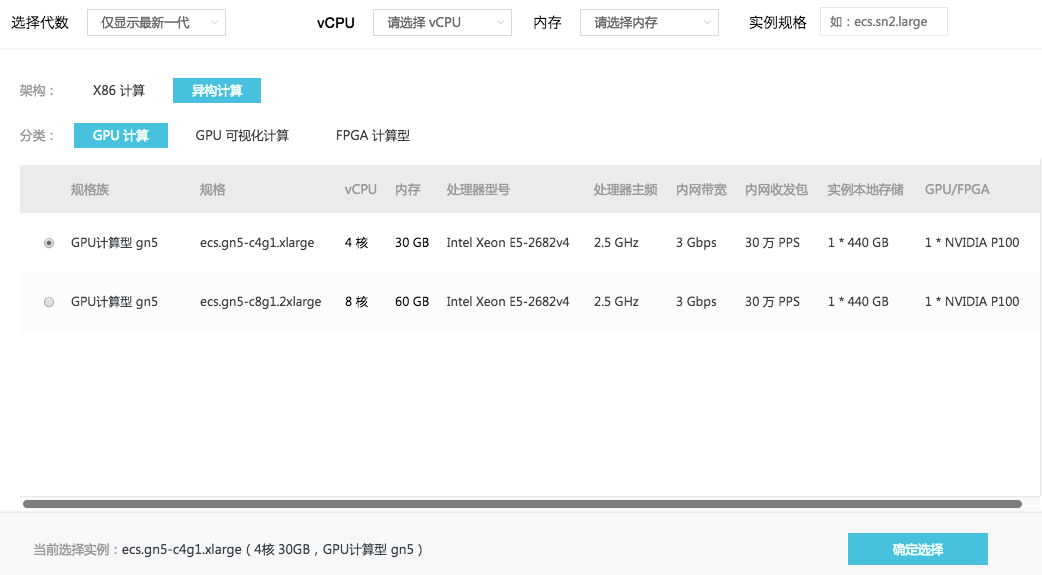
Worker节点ECS实例规格:指定 Worker 节点所运行的包含GPU的 ECS 实例规格,默认为 ecs.gn5-c4g1.xlarge。具体配置可以查看ECS规格文档。
-
部署GPU节点的可用区:指定 GPU节点可以部署的可用区,请根据具体地域选择。
-
ECS系统镜像:目前指定 centos_7。
-
Worker节点数:指定 Worker 节点数,默认为 2,支持后期扩容。
-
ECS登录密码:所创建的 ECS 实例可通过此密码登录,请务必牢记密码。
3. 单击 创建, 启动部署
这样,部署请求已经成功提交。 可以单击 进入事件列表 实时监控部署过程
4. 点击概览查看,部署完成后的输出结果
通过输出结果中返回的信息,可以对 Kubernetes 集群进行管理:
-
APIServer_Internet:Kubernetes 的 API server 对公网提供服务的地址和端口,可以通过此服务在用户终端使用 kubectl 等工具管理集群。
-
AdminGateway:可以直接通过 SSH 登录到 Master 节点,以便对集群进行日常维护。
-
APIServer_Intranet:Kubernetes 的 API server 对集群内部提供服务的地址和端口。
5. 通过通过 kubectl 连接 Kubernetes 集群 , 并且通过命令查看GPU节点
kubectl describe node {node-name}Name: cn-beijing.i-{name}Role:...Addresses: InternalIP:192.168.2.74Capacity: alpha.kubernetes.io/nvidia-gpu: 1 cpu:4 memory:30717616Ki pods:110Allocatable: alpha.kubernetes.io/nvidia-gpu: 1 cpu:4 memory:30615216Ki pods:110...
可以看到总共的和可分配的GPU数量都为1。
部署GPU应用
最后我们部署一个基于GPU的TensorFlow Jupyter应用来做一下简单的测试,以下为我们的Jupyter的部署配置文件**jupyter.yml**
---apiVersion: extensions/v1beta1kind: Deploymentmetadata: name: jupyterspec: replicas:1 template: metadata: labels: k8s-app: jupyter spec: containers: - name: jupyter image: registry-vpc.cn-beijing.aliyuncs.com/tensorflow-samples/jupyter:1.1.0-devel-gpu imagePullPolicy: IfNotPresent env: - name: PASSWORD value: mypassw0rd resources: limits: alpha.kubernetes.io/nvidia-gpu: 1 volumeMounts: - mountPath: /usr/local/nvidia name: nvidia volumes: - hostPath: path: /var/lib/nvidia-docker/volumes/nvidia_driver/375.39 name: nvidia---apiVersion: v1kind: Servicemetadata: name: jupyter-svcspec: ports: - port:80 targetPort:8888 name: jupyter selector: k8s-app: jupyter type: LoadBalancer
Deployment配置:
-
** alpha.kubernetes.io/nvidia-gpu ** 指定调用nvidia gpu的数量
-
** type=LoadBalancer ** 指定使用阿里云的负载均衡访问内部服务和负载均衡
-
为了能让GPU容器运行起来,需要将Nvidia驱动和CUDA库文件指定到容器中。这里需要使用hostPath,在阿里云上您只需要将hostPath指定到/var/lib/nvidia-docker/volumes/nvidia_driver/375.39即可,并不需要指定多个bin和lib目录。
-
环境变量** PASSWORD ** 指定了访问Jupyter服务的密码,您可以按照您的需要修改
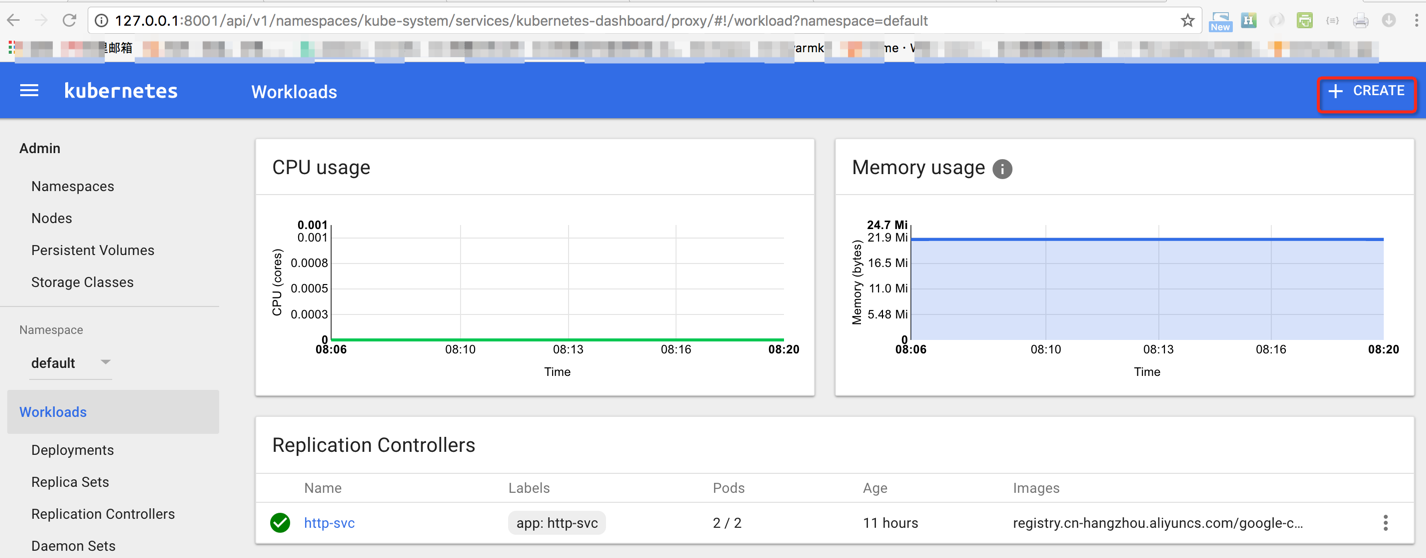
1. 按照文档介绍的方式连接Kubernetes Web UI, 点击 CREATE 创建应用
2. 单击 Upload a YAML or JSON file。选择刚才创建的 jupyter.yml 文件
3. 待部署成功后, 在 Kubernetes Web UI 上定位到 default 命名空间,选择 Services。
可以看到刚刚创建的 jupyter-svc 的 jupyter 服务的外部负载均衡地址(External endpoints)
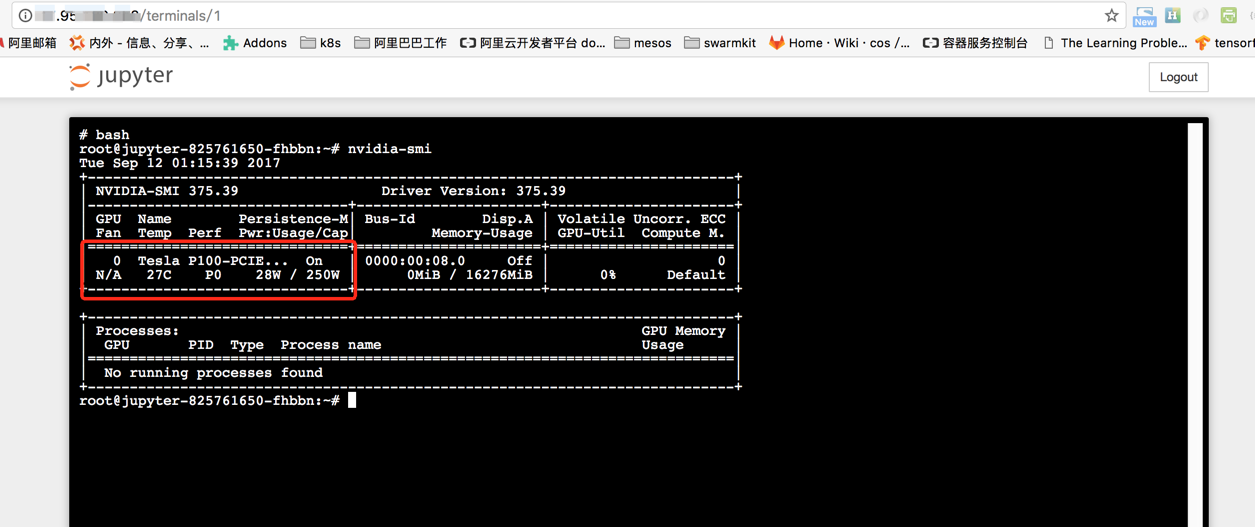
4. 点击外部负载均衡的地址,您就可以直接访问到Jupyter服务, 通过web Terminal内执行nvidia-smi命令查看容器内GPU设备状况。我们可以看到当前的容器里已经分配了一块Tesla P100 的GPU卡。
这样,您就可以正式开始自己的深度学习之旅
总结
利用阿里云容器服务的Kubernetes+GPU部署方案,您无需操心复杂Nvidia驱动和Kubernetes集群配置,一键部署,不出十分钟就可以轻松获得阿里云强大的异构计算能力和Kubernetes的GPU应用部署调度能力。这样您就可以专心的构建和运行自己的深度学习应用了。欢迎您尝试和体验。